python爬取校园集市帖子并生成词云图
注:本篇需要python基础,json基础
前言:上篇我们学习了怎么用python获取百度热搜,在这篇中,我们将进一步学习,利用python爬取校园集市帖子并生成词云图
[toc]
灵感背景:经常在群里看见机器人转发的校园集市帖子,于是想要爬取下来分析一下
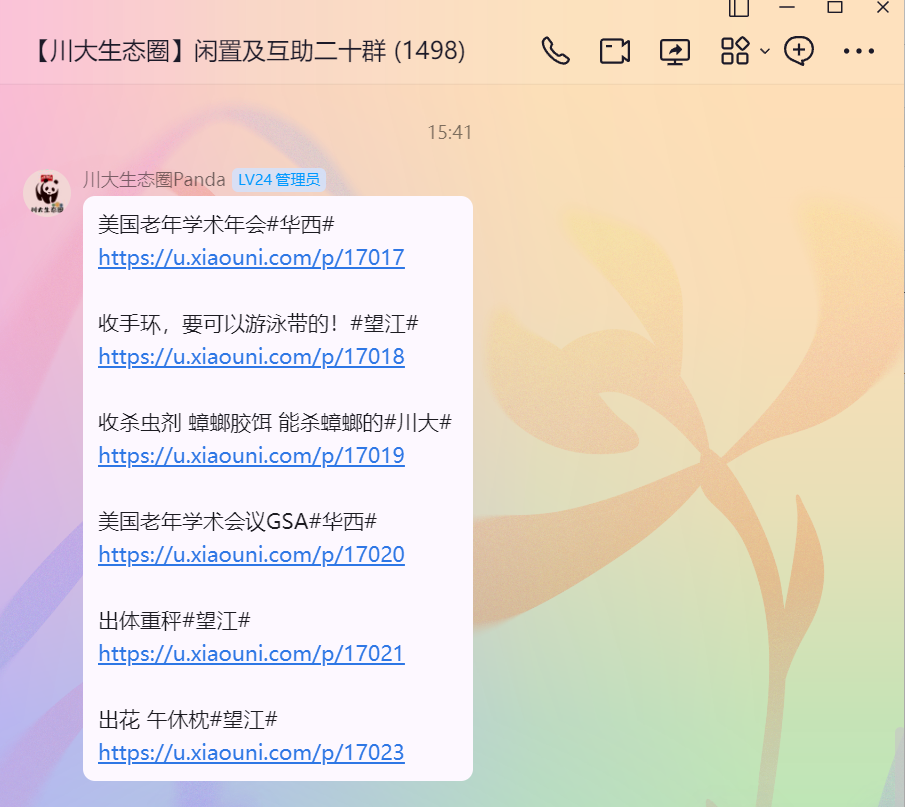
第一步,分析请求
点击链接进入浏览器页面
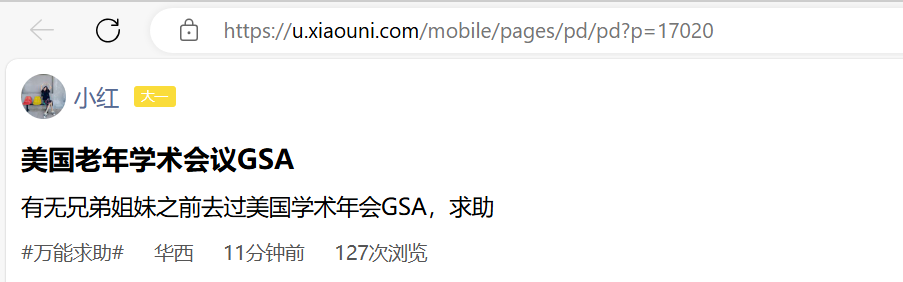
按下F12打开浏览器开发者界面
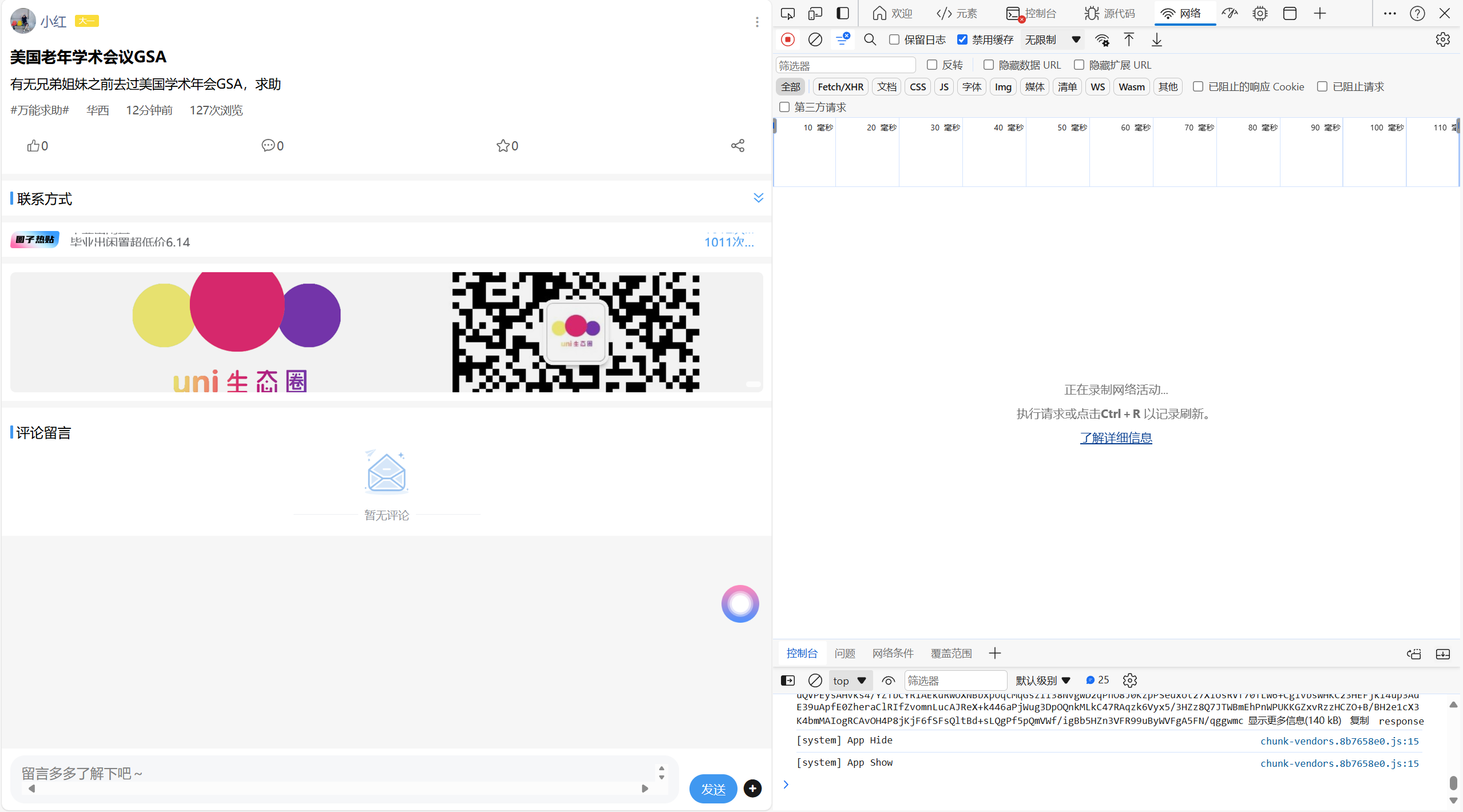
点击网络,按下F5刷新
刷新后如图所示
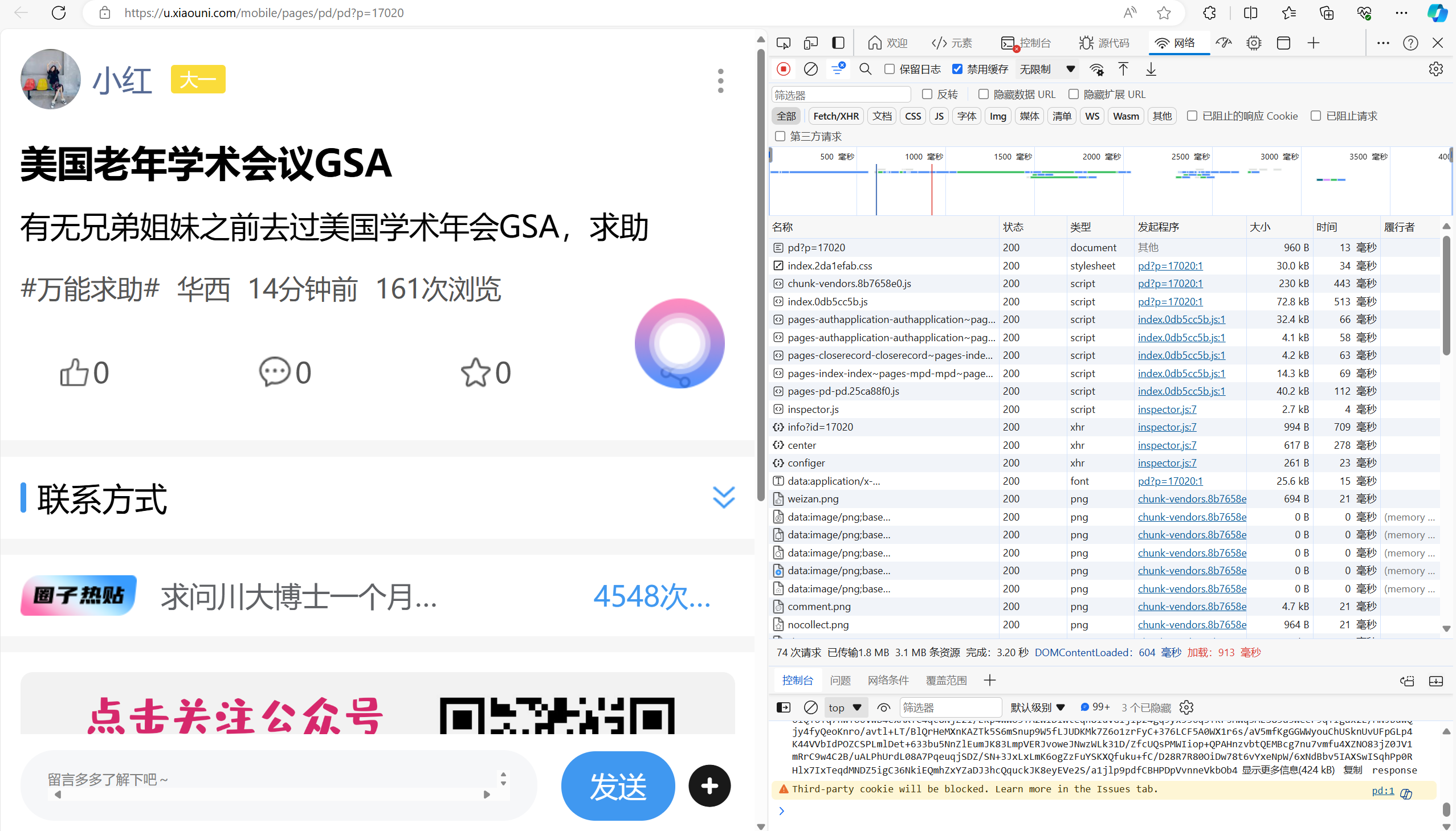
点击预览,寻找目标请求
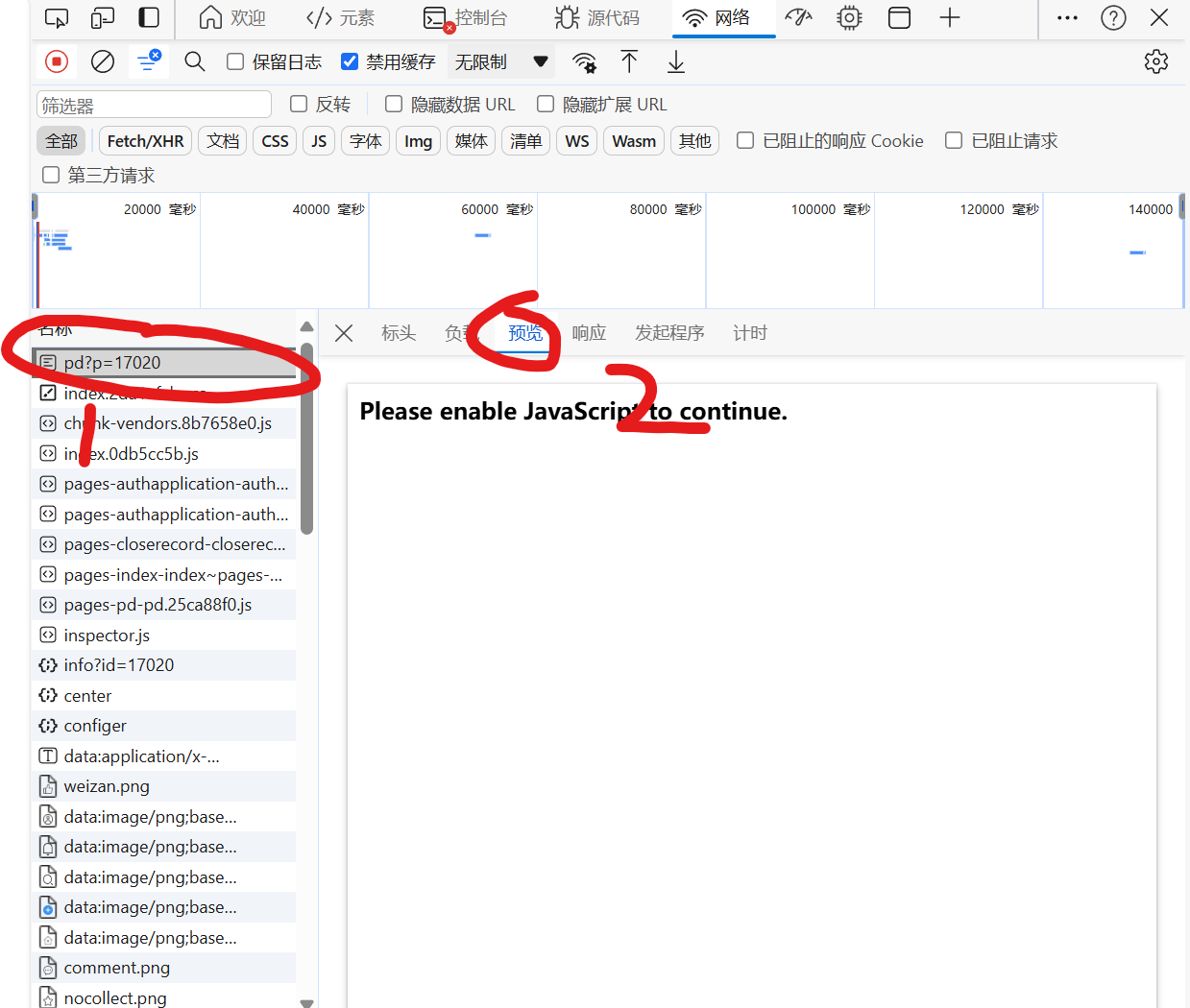
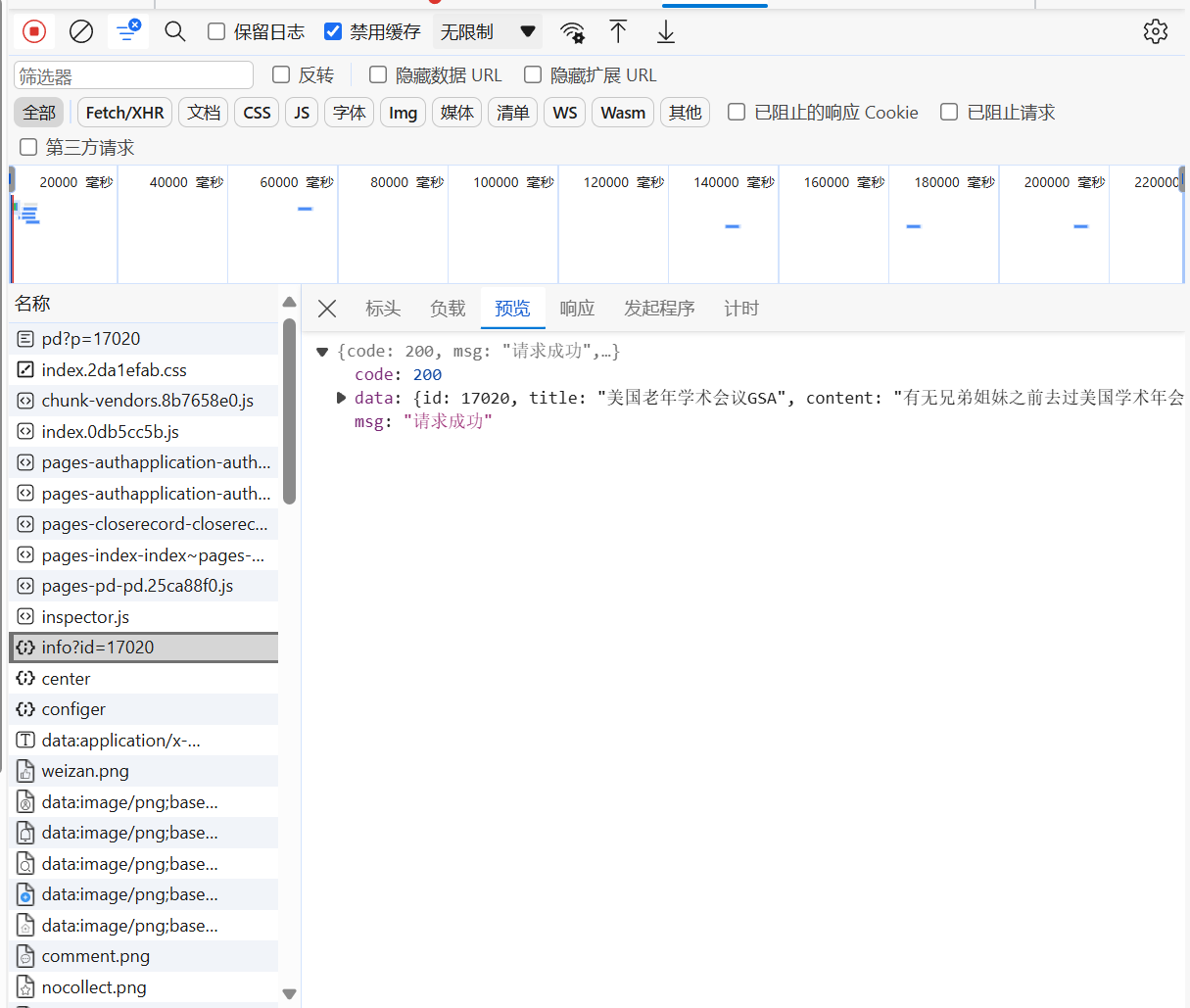
最终找到请求
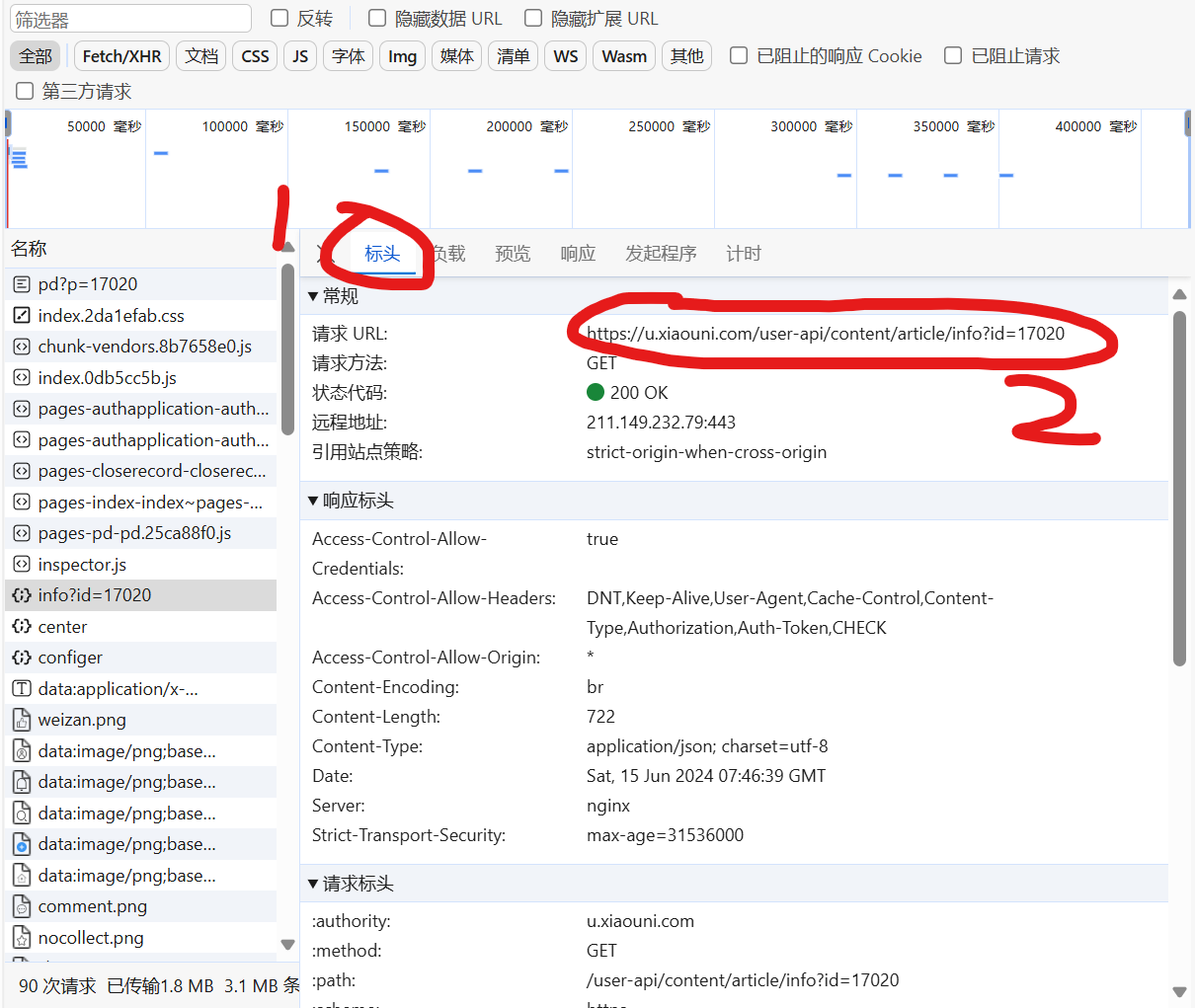
点击标头,获取url
第二步,编写代码
1 | |
结果如下
1 | |
我们发现这个是json格式的内容,而且是以unicode进行编码的结果
我们进一步修改代码,获取帖子标题和内容
1 | |
结果如下
1 | |
成功获取集市帖子
第三步,批量获取帖子
我们改进代码,获取最近的300条帖子,写到一个txt文件中方便后续使用
1 | |
结果如下
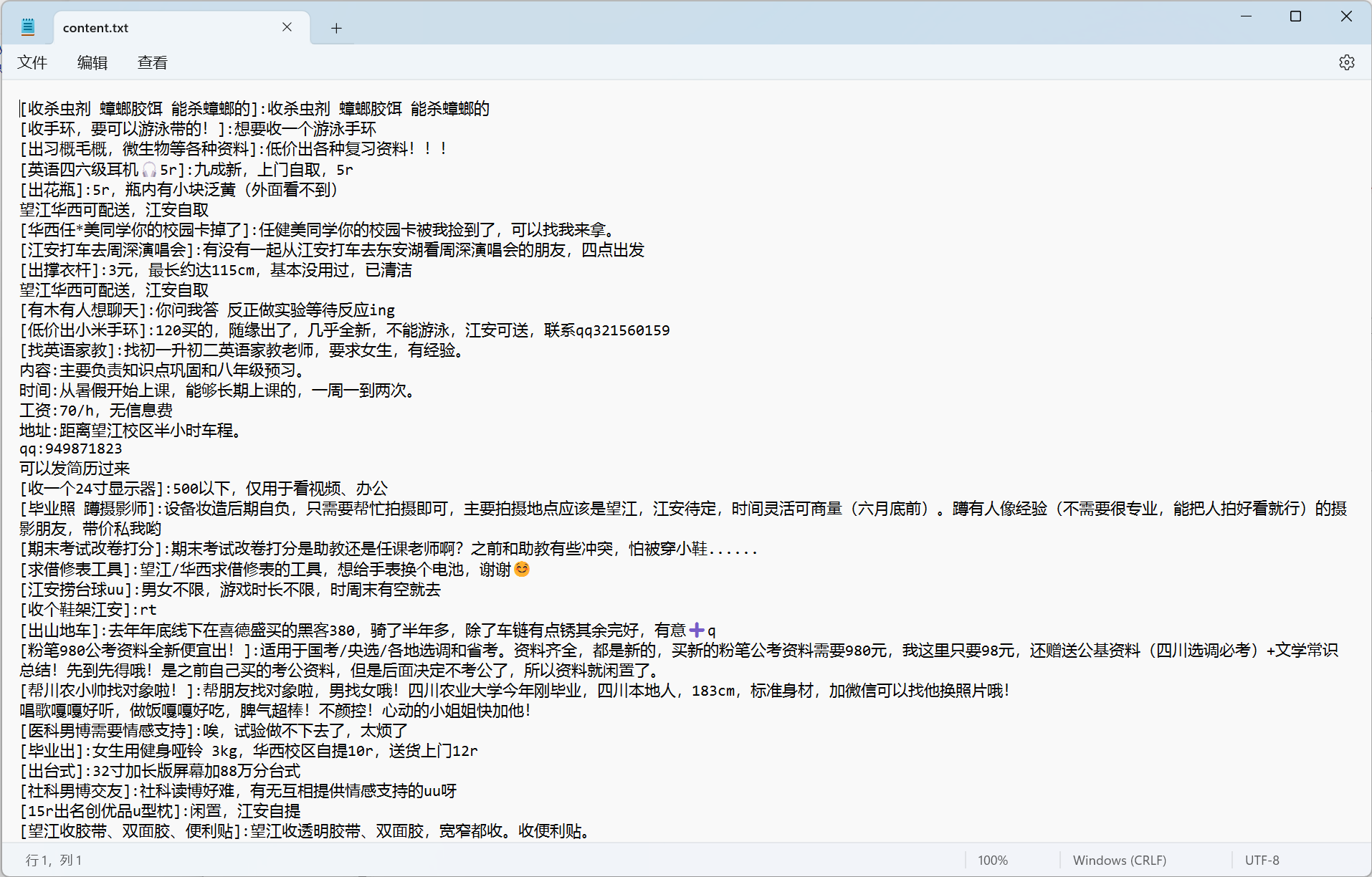
第四步,绘制词云图
编写一个新的python脚本,将上面获取到的帖子内容绘制成词云图
这步需要安装jieba库(注:这里只是jieba库的简单运用,并未排除一些无意义的词,若要更加出色的表现,可进行jieba库的学习)和wordcloud库
1 | |
接下来编写代码
1 | |
打开1.png结果如下 (词语出现频率越高,在词云图中的字就越大)

成功实现词云图绘制
python爬取校园集市帖子并生成词云图
https://www.blog.jeanhua.cn/2024/06/15/986d735abcc0/